
(Jay) Digvijay Wadekar
Here is a brief description of a few selected projects.
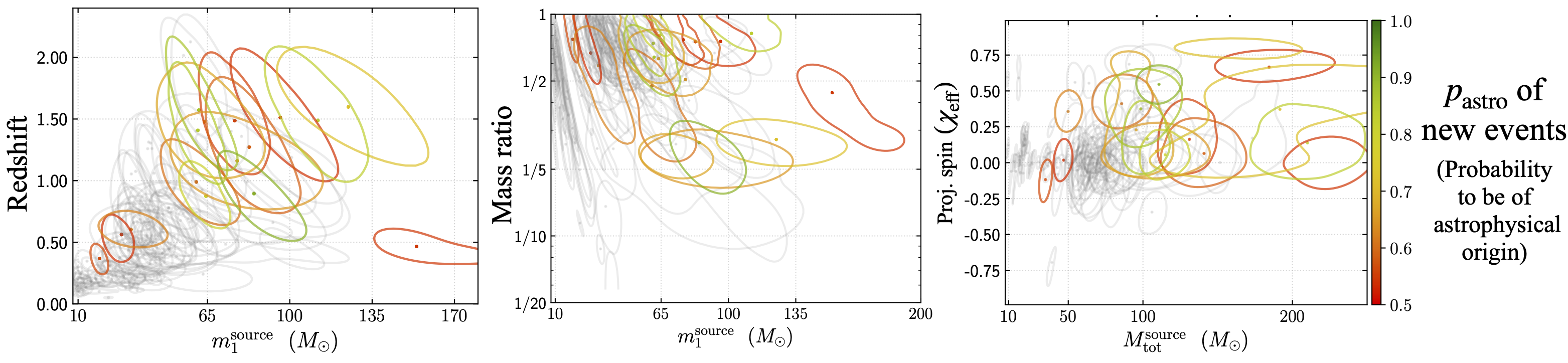
Nearly all of the previous gravitational wave (GW) searches in the LIGO-Virgo data include GW waveforms with only the dominant quadrupole mode, i.e., omitting higher-order harmonics which are predicted by general relativity. We detected new black hole mergers in the LIGO-Virgo O3 data from a novel search pipeline that includes the higher-order harmonics. The black holes in some of the new detections have astrophysically interesting properties such as occupation of the pair-instability mass gap, high-redshift (1 < z < 2), and positive effective spins. Apart from the search with higher harmonics, I also performed a GW search for exotic objects with large tidal deformabilities (e.g., boson stars and black holes with axion clouds).
Here is the link to the PDF of a recent talk
The video below is from one of my online talks2. Interpretable ML techniques for cosmology and astrophysics
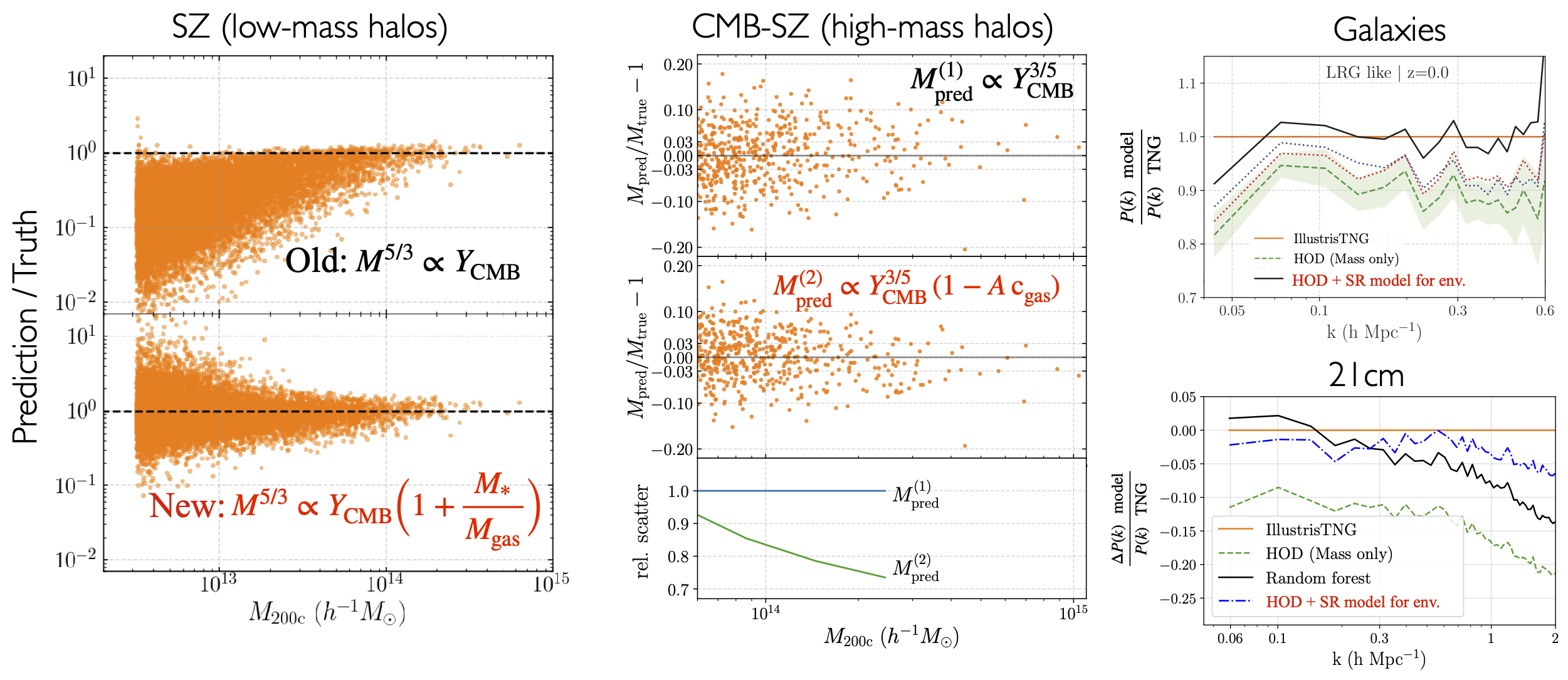
Finding low-scatter relationships in properties of complex systems (e.g., stars, supernovae, galaxies) is important to gain physical insights into them and/or to estimate their distances/masses. As the size of simulation/observational datasets grow, finding low-scatter relationships in the data becomes extremely arduous using manual data analysis methods. We used machine learning techniques to expeditiously search for such relations in abstract high-dimensional data-spaces. Focusing on clusters of galaxies, we found new scaling relations between their properties obtained using ML. Our relations can enable more accurate inference of cosmology and baryonic feedback from upcoming surveys of galaxy clusters such as ACT, SO, eROSITA and CMB-S4. We also explored the use of ML tools to model the galaxy-halo connection.
The video below is from one of my online talks
3. Using gas-rich dwarf galaxies to probe alternatives to cold, collisionless dark matter
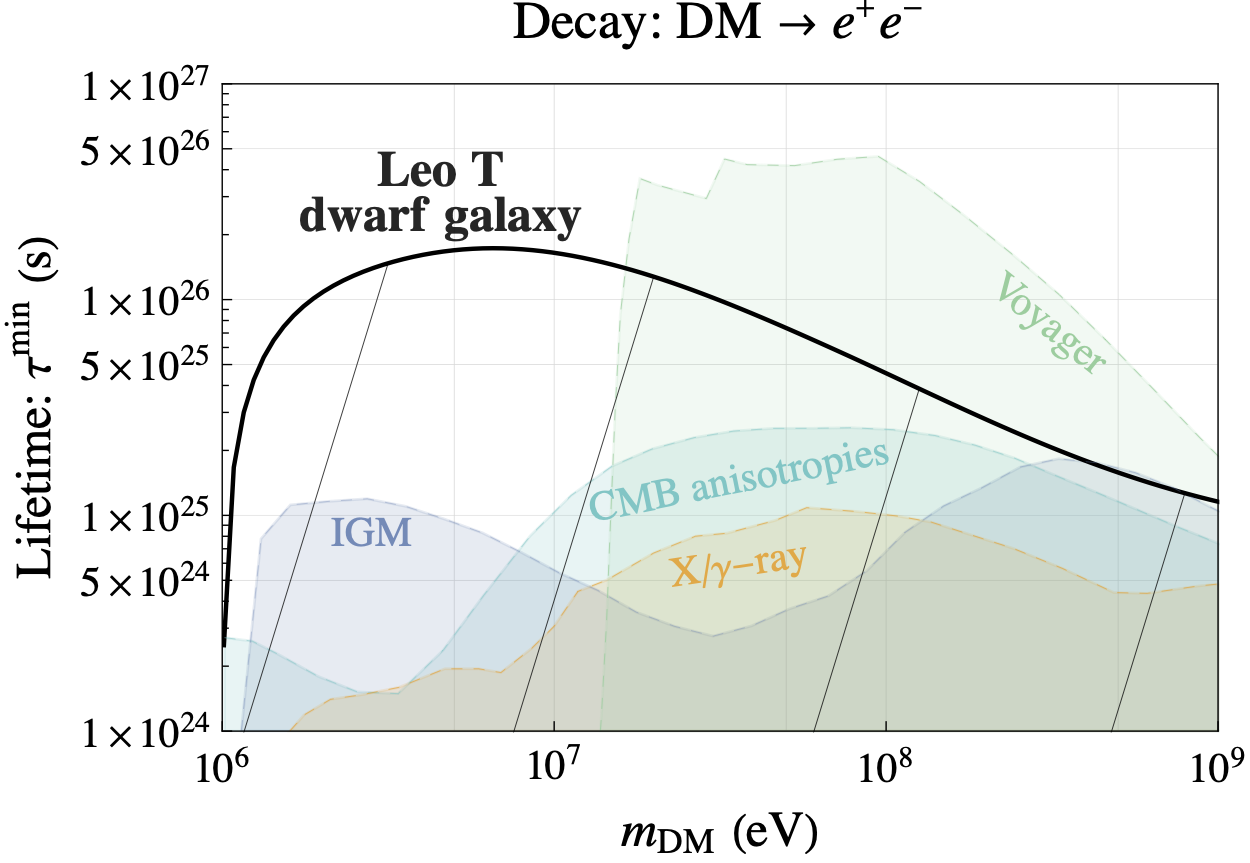
Gas-rich dwarf galaxies located outside the virial radius of their host are relatively pristine systems. Due to the ultra-low radiative cooling rate of gas in these dwarfs, they are very strong calorimetric probes of energy injection by alternative dark matter (DM) candidates. We used these dwarfs to obtain strong constraints on popular DM models like millicharged DM, axion like particles (ALPs) and primordial black holes (PBHs). For dark photon DM and for some DM decay models, these dwarfs gives stronger constraints than all the previous literature. Observations of gas-rich dwarfs from current and upcoming 21cm and optical surveys (e.g., Rubin observatory, Roman telescope) therefore open a new way of probing DM.
Here is the link to the PDF of a recent talk and below is the video
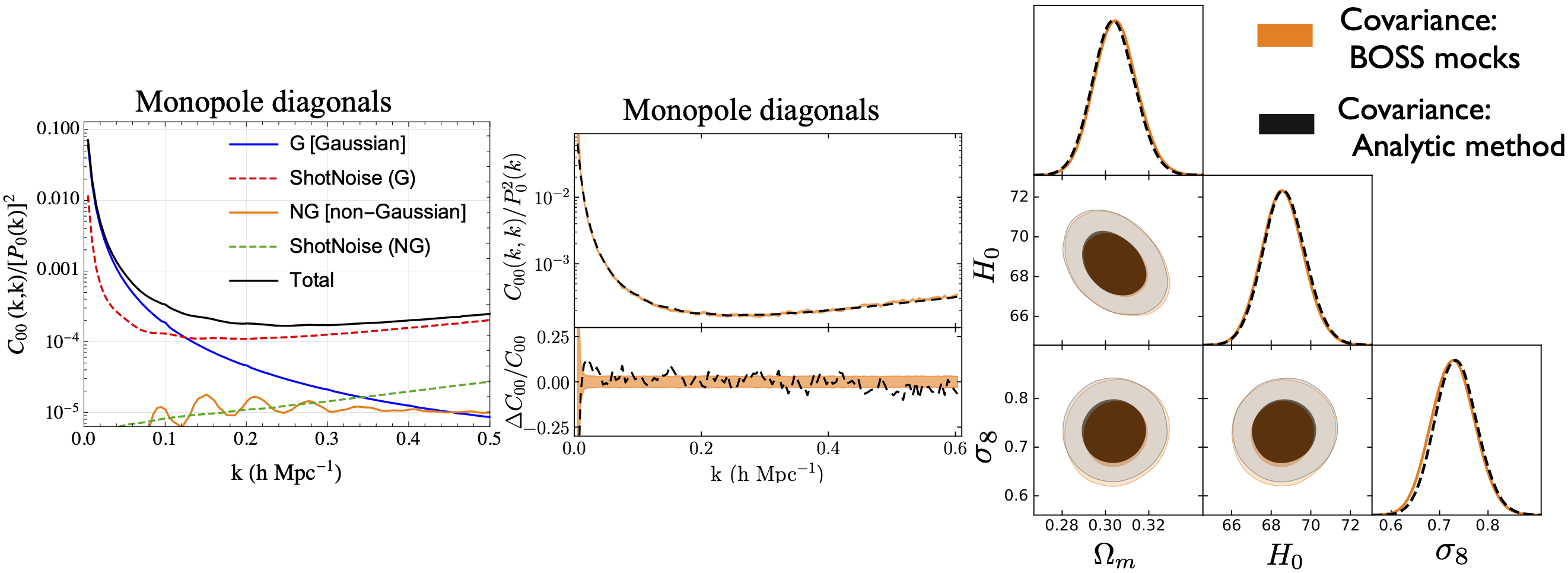
4. Analytic covariance matrices for upcoming spectroscopic galaxy surveys
The video below is from one of my online talks